“ 虚拟数字人是AI+元宇宙的桥梁”
一直以来,AI产业一直难以有非常稳定形态的产品落脚,让它成为一个行业,更多的是服务其它方方面面,以至于一个ai公司,永远都是ai+公司,或者一个人脸识别公司,或者一个语音识别公司,或者一个安防公司,本质上,这些都不能算未来意义的AI公司。AI的形态应该是什么,是机器人,是机器狗,是虚拟机器人,是机器人工厂。
但是因为智能化程度太低,很多所谓的“ai公司”,都不足以称为ai公司。
AI产品,或者ai公司除了迎合现在这波算法应用套现之外,应该做什么样的产品?让ai成为一个行业,像汽车行业一样有自己稳定的形态?
机器人、虚拟数字人是两个很好的形态。前提是要足够智能。
01 元宇宙原生
元宇宙的热风刮起,经历了短时间的狂热和炒作,又被抨击一波之后,总得回归理性。但人又是喜欢想象的动物,有想象力的东西,更值得理性去想象可行性。
既然元宇宙的概念来了,是一张新的网络,一个新的虚拟世界,这个世界需要真实的人虚拟化参与,也需要物联世界虚拟化进去,但是这些都不是元宇宙原生的,这些东西本来就有,不过是虚拟化了一下,除了一个虚拟的空间之外,这个虚拟世界中,有什么是原生的吗?虚拟数字人,就可以是原生为元宇宙。
现实物理世界中,人和人的面对面沟通很真实,在网络世界,我们已经开始分不清正在聊天的美女是否真的是个美女,随着智能化程度的提升,与你聊天的可能是个机器人,而在元宇宙虚拟世界,和你牵手走在虚拟路上的,可能真的是个机器人,尽管看似还没那么快。
这里不禁要问,那就是虚拟世界在虚拟世界忽悠人,还有什么价值?虚拟数字人究竟只是个噱头还是有实际的价值?
02 虚拟数字人的价值与市场规模
现实世界的虚拟数字人应用其实已经开启,而且已经应用在非常多行业场景中。为加快推动虚拟数字人技术和产业创新发展,中国人工智能产业发展联盟和中关村数智人工智能产业联盟数字人工作委员会在2020年发起虚拟数字人推进计划,致力于开展虚拟数字人技术研究、标准制定、评估测试、合作交流、成果发布及生态建设工作。并在2020年12月推出了《2020 年虚拟数字人发展 白皮书》。
虚拟数字人发展经历可以总结为4个阶段,从萌芽、探索、初级、成长四个阶段。

2021年,元宇宙概念爆发,facebook改名meta、微软入局元宇宙,11月,英伟达推出了omniverse开发平台,将加速虚拟世界开发。国际巨头的一系列动作直指元宇宙。英伟达的发布会黄仁勋的数字替身更是在发布会过后都没有人看出,等到官方公布才大为震惊

虚拟数字人的价值有哪些?直接看产业图谱
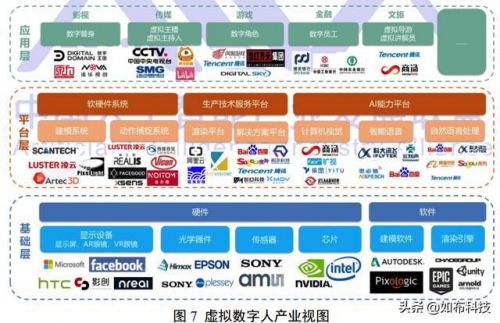
(1)影视制作,无论是数字人替身,还是动画形象的,都是影视制作的很好素材。
(2)在传媒领域,还可以使用虚拟主播、虚拟主持人进行播放
(3)在游戏中,可以作为非玩家角色npc丰富游戏内容
(4)在金融领域,虚拟数字人还可以作为数字员工提供引导、问答对话等
(5)在文旅中作为虚拟导游讲解员,丰富旅游体验。
(6)在智慧车舱、教育领域都有非常有前景。
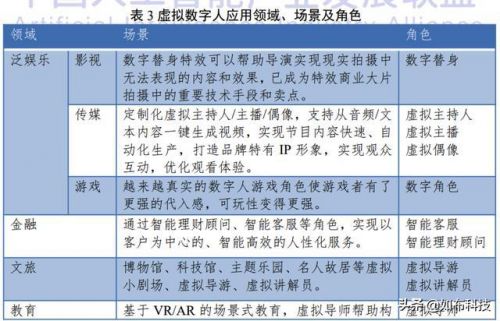

这些价值,不外乎还是在效率上更高、体验上更加友好
在这些应用场景下,虚拟数字人还是一个不小的市场,根据量子位《虚拟数字人深度产业报告》,2030年,我国虚拟数字人整体市场规模将达到2700亿,身份型虚拟数字人规模达到1750亿,服务型虚拟数字人规模在950亿左右,面对这么大市场规模的。
服务型数字人、身份型数字人
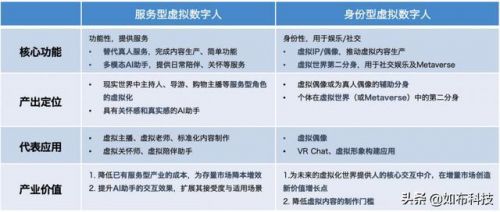
来源:《虚拟数字人深度产业报告》,量子位
03 AI虚拟数字人构建
虚拟数字人构建有两种方式,包括通过真人驱动、计算驱动。
真人驱动是通过摄像机捕捉真人的动作和表情,输出虚拟形象的方式,这种方式其实是在传统计算机绘图的基础上,加入动作捕捉技术,由于基于深度学习的图像识别技术越来越强大,再不需要通过各种复杂传感器,普通的相机都可以获取非常高精度的定位信息。

真人驱动的虚拟人构建一般需要5个主要的步骤:
(1)设计虚拟人形象以及绘制IP、真人偶像原画,选择动作关键点进行全身建模;
(2)对形象关键点和真人关键点进行绑定;
(3)通过如摄像头+图像识别,捕捉真人的形态、表情、动作等并识别关键点变化
(4.)真人表演实时驱动虚拟数字人表演,通过语音合成形成特定设置的语音。
(5)生成内容或者直播互动。
计算驱动的虚拟人构建是通过深度学习模型生成表情、身体、动作、语音等,一般需要经过以下的步骤(来源:《虚拟数字人深度产业报告》):
(1)形象设计。扫描真人形态及表演、采集驱动数据
利用多方位摄像头,对通用/特定模特进行打点扫描(视最终需求可进行全身或局部扫描),采集其说话时的唇动、表情、面部肌肉变化细节、姿态等数据
(2)形象建模,进行绑定
设计所需的模型,或基于特定真人进行高还原度建模。进行关键点绑定。当需要基于真人照片生成虚拟内容时,一类做法是将通用的人脸模型迁移至该真人照片上,形成虚拟形象,实质为表情迁移。另一类则是生成动漫类效果,基于预先设置的形象分类算法,将真人照片中的眼型、发型等元素进行分类,并与预先设置的动漫元素进行匹配,最终生成动漫式的虚拟形象。
(3)训练各类驱动模型
利用深度学习,学习模特语音、唇形、表情参数间的潜在映射关系,形成各自的驱动模型与驱动方式。充足的驱动关键点配合以精度较高的驱动模型,能够高还原度的复原人脸骨骼和肌肉的细微变化,得到逼真的表情驱动模型。
如语音-唇形,语音-驱动。动作、手势等驱动大多依靠人为现场指令或预设置驱动。对于需对特定真人定制化的数字化虚拟数字人,部分公司会基于在通用驱动模型的基础上,结合少量真人驱动数据训练定制化驱动模型。这种情形可视作预训练模型+小样本学习。
(4)内容制作
基于语音合成技术TTS,将文本生成为语音,基于语音,利用驱动模型以及利用生成对抗模型GAN输出数字人的每帧图片,通过时间戳,将语音和数字人图像结合
(5)渲染,生成最终形象
另外,针对特定应用场景,需要知识做支撑的,需要进行对话的,还需要加入语音识别,知识图谱等。
近年来,基于transformer的大模型,如gpt-3,国内智源的“悟道2.0”等大模型,以及融合了多模态的大模型,作为基模型,支撑下游虚拟数字人的构建,让虚拟数字人的构建更加逼真。
04 AI虚拟数字人+元宇宙&AIGC
乘着元宇宙的风口,ai虚拟数字人作为元宇宙中的交互实体,有非常大的潜力,在现阶段,虚拟数字人更多的是在现有的业务,比如传媒、直播、金融等领域有诸多应用。起到服务、身份代替等功能。
在元宇宙中,这两种形态的应用依然存在,当未来元宇宙入口的硬件得到大规模普及,众多人进入到元宇宙中,虚拟数字人依然可以在元宇宙中充当如导游、导购、讲解等等主动服务功能,更像一个游戏中的NPC,而在元宇宙中依然有诸多真实玩家,这些玩家的数字人更多的是身份替代,可以代替我们在元宇宙中开会、上课学习、远程聚会社交等等。可以说AI虚拟数字人是元宇宙在软件层面的基础设施。
在元宇宙中,诸多的内容是由于人来创造,但是更加丰富的元宇宙除了人,还可以由于虚拟人在创造,这就是从UGC(用于生产内容)向AIGC(人工智能生产内容)转变的一种形态。在元宇宙中,虚拟数字人也可以参与到内容的创作中,哪怕是对在元宇宙中产生了一些行为动作,而更加智慧的人工智能,特别是未来自主意识出现之后,人工智能将直接“存活”在元宇宙之中,元宇宙,变成虚拟数字人的宇宙,而真实人其实是元宇宙的“外来物种”。当然,这个展望,可能还需要很长时间。






