原标题:北大刘利斌团队斩获 SIGGRAPH Asia 2022 最佳论文奖:用语音和文字驱动数字人打手势
2022 年 12 月 6 日,SIGGRAPH Asia 2022 大会官方公布了最佳论文等多个奖项。其中,最佳论文奖由北京大学刘利斌团队的论文“Rhythmic Gesticulator: Rhythm-Aware Co-Speech Gesture Synthesis with Hierarchical Neural Embeddings”获得,论文第一作者为北京大学 2020 级研究生敖腾隆。

在日常生活中,我们的语言行为时常会伴随着一些非语言的动作进行:在公开演讲时使用手势让内容更有感染力,一个突然降临的好消息令人不由自主地鼓掌,陷入沉思时的来回走动和紧握的拳头......这些非语言的动作像是“调味剂”,有时可以帮助形象化我们口头所说的一件事物,强化语言所传递的态度,让人类的表达才会更加生动且高效。
在这项工作中,刘利斌团队提出了一个新的由语音和文字来驱动3D上半身人体模型进行手势表演的跨模态生成系统,通过输入一段时序同步的语音和文字,系统就能自动生成与之对应的上半身手势。
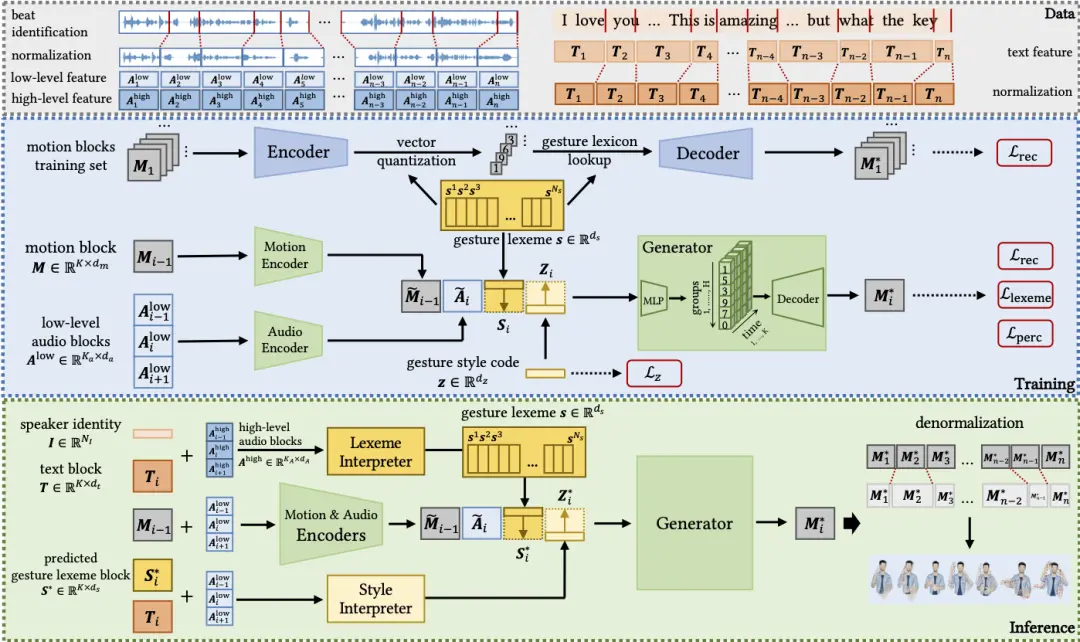
图 1:系统概览图
一段手势动作由单个手势单元(gesture unit)组成,其中,每个手势单元可根据语调点、例如强调重音等,被划分为单个手势阶段(gesture phase),每个手势阶段就代表了一小段特定的动作,比如抬手、摆臂等,在语言学中,这些手势阶段通常被称为手势词(gesture lexeme)。由于日常交流中的手势词数目有限,将这些手势词进行集合后,即可获得一个手势词典(gesture lexicon)。
特定演讲者在讲述过程中使用的手势词,就是手势词典中的子集,每个手势词上还会叠加轻微的变动(variation),研究人员通过假设此类表动无法直接由输入推断,将其编码为一些隐变量(latent variable),这些代表轻微变动隐变量的手势风格编码(gesture style code)。演讲者风格不同,因此手势风格编码一般跟演讲者的风格相关,会受到演讲者的音调等低层次音频特征影响。

图 2:系统所使用的字符模型
对此,该系统依据手势相关的语言学研究理论,从韵律和语义两个维度出发,对语音文字和手势之间的关系进行建模,从而保证生成的手势动作既韵律匹配又具备合理的语义。
基于上述理论,刘利斌团队梳理了一个层次化结构:需要检测节奏点(beat),划分出手势词,每个手势词本质上已具备明确含义,由输入语音的高层次语义特征决定;而基于每个手势词的变动,即手势风格编码,应该与输入语音的低层次音频特征,例如音调、音强等因素相关。
因此在系统中,研究人员首先需要分离出不同层次的音频特征,由高层次音频特征决定手势词,低层次音频特征决定手势风格编码。当推断出整段音频对应的手势词和手势风格编码序列后,依照检测出的节奏,研究团队会显式地将上述手势块“拼接”起来,确保生成的手势韵律和谐,同时明确的手势词和手势风格编码保证了生成手势的语义正确性。

图 3:第一行为右手高度、第二行为手速、第三行为手半径的样式编辑结果,右侧图表显示编辑输入(平线)和输出运动的相应值,箱形图显示输出的统计数据
系统由数据(Data)模块、训练(Training)模块和推断(Inference)模块三个部分组成。
其中, 数据模块的任务是对语音进行预处理,根据节拍将语音分割成标准化块,并从这些块中提取出语音特征。此次研究中共使用了三个数据集,分别是 Trinity 数据集、TED 数据集、以及为这项工作所收集的中文数据集。
训练模块会从标准化运动块中学习手势词汇,并训练生成器合成手势序列,当中要考虑的条件就包括了手势词典、风格代码以及先前运动块和相邻语音块的特征。随后的推理模块中,会使用解释器将语音特征转换为手势词典和风格代码,并使用学习生成器来预测未来的手势。
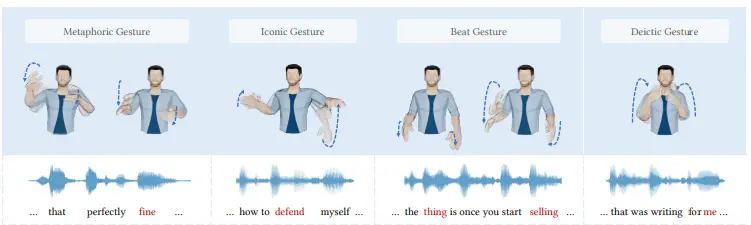
图 4:借助系统从 Trinity Gesture 数据集的四个样本语音摘录中合成的手势的定性结果,在说“好”时会做出一个隐喻的手势,当在捍卫时会做出一个标志性的手势,遇到 thing 和 selling 等词会做出节拍手势,当说到“我”时会出现指示手势
为了验证该研究是否可以实现“高层次音频特征决定偏语义的手势词,低层次音频特征则影响当前手势词内的轻微变动”,刘利斌团队通过找到一类相似语义的高层次音频特征,其对应的文本为 many、quite a few、lots of、much、and more 等,就这类高层次音频特征的每个音频特征对应生成的手势序列,并对这些手势序列编码到手势词典空间进行可视化(图 4)。
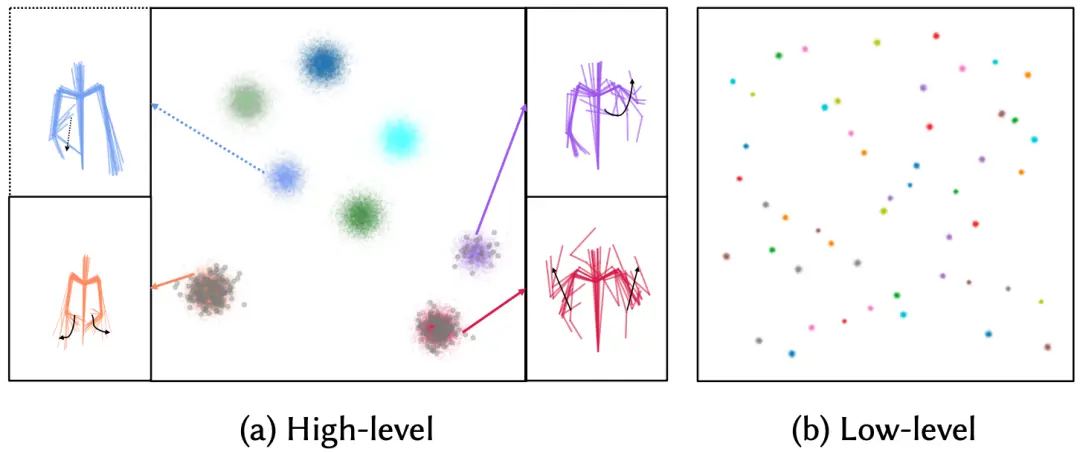
图 5:手势词典空间动作特征向量的 t-SNE 可视化结果
可以发现,手势动作序列仅出现在特定的手势词内,当中所出现的手势词对应的动作,图 5(a)中的红、橙和紫色所对应的骨骼动作),的确为“many、lots of、 etc”的意思表征。与之相对应的是,当对同类的低层次音频特征进行可视化后,如图 5(b)可见,属于该低层次音频特征类的动作序列不再集中于特定几类,而分散到整个手势词典空间内,由此可以验证“高层次音频特征决定偏语义的手势词”。
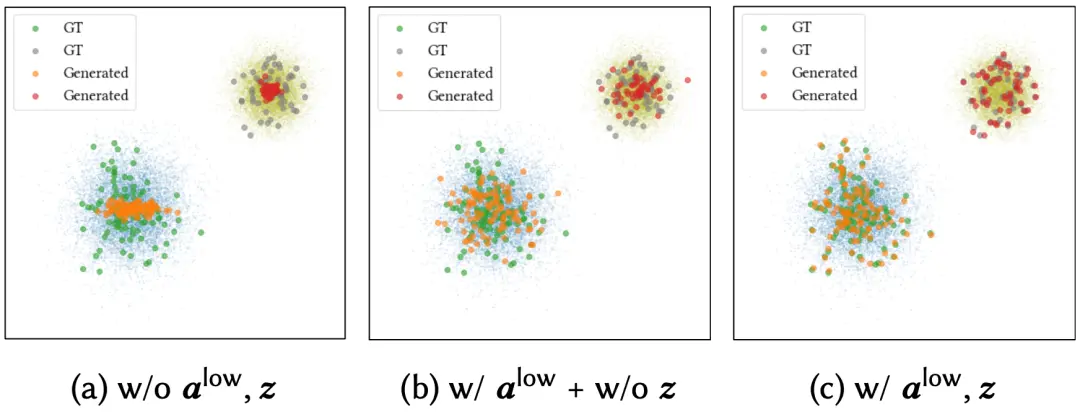
图 6:手势词典空间动作特征向量的 t-SNE 可视化结果
当不加入手势风格编码 z 时,如图 6(a)所示,所生成的手势密集地集中在当前手势词的类中心,于真值分布存在较大差距。当加入手势风格编码后,如图 6(c)所示,所生成的手势跟真值分布接近,这说明手势风格编码已成功建模了手势词的类内轻微变动。由此可以看到,手势风格编码主要由低层次音频特征推断得到,从而证明“低层次音频特征影响当前手势词内的轻微变动”。
除了上述结果外,该系统还具备以下几项特性:
跨语言生成,即使面对数据集没有的语言,也能生成韵律和谐的手势;长音频生成,能够面对较长的输入音频序列
手势风格编辑,通过加入控制信号可以控制生成手势的风格
无声状态下尽量减少多余的手势动作
输入一些特定音乐可鲁棒地捕捉其节奏并随之“摆动”

刘利斌,北京大学人工智能研究院前沿计算研究中心助理教授,2009年本科毕业于清华大学数理基础科学专业,后转向计算机科学与技术专业,2014年获得清华大学博士学位,曾在加拿大不列颠哥伦比亚大学及美国迪士尼研究院进行博士后研究,之后加入 DeepMotion Inc. 任首席科学家。刘利斌教授的主要研究方向是计算机图形学、物理仿真、运动控制以及相关的优化控制、机器学习、增强学习等领域,曾多次担任图形学主要国际会议如 SIGGRAPH、PacificGraphics、Eurographics 等的论文程序委员。







