“Baichuan 2开源模型发布之后,用LLaMA 2作为开源模型的时代就已经过去了。”
2023年9月6日,王小川在百川智能大模型发布会上如此说道。
此次发布会,百川智能宣布正式开源微调后的Baichuan 2-7B、Baichuan 2-13B、Baichuan 2-13B-Chat与其4bit量化版本,并且均为免费可商用。同时,百川智能还开源了模型训练的Check Point,并宣布将发布Baichuan 2技术报告,详细介绍Baichuan 2的训练细节,帮助大模型学术机构、开发者和企业用户更深入地了解其训练过程。
百川智能于今年4月份由王小川和茹立云联合创立,旨在打造中国版的OpenAI基础大模型及颠覆性上层应用。创立至今,百川智能先后发布了70亿参数的baichuan-7B,130亿参数的 baichuan-13B,以及530亿参数的大模型 baichuan-53B。
全明星创业团队,估值超5亿美元
在创立百川智能之前,王小川的主要身份是搜狗创始人,曾主持开发了搜狗搜索、搜狗输入法、搜狗浏览器等产品,先后拿到过阿里巴巴和腾讯的战略投资,并于2017年成功带领搜狗在美股上市。百川智能的另一位创始人茹立云则是搜狗前COO,曾于2018年创立人工智能教育公司葡萄智学。
据王小川透露,百川智能在创立之初便获得5000万美元启动资金,主要来自王小川与其业内好友的个人支持。而根据企查查数据,成立仅一个月后,百川智能又获得了众为资本,顺为资本,小米集团,红点中国,腾讯投资等十余家明星基金的天使轮投资。王小川透露,百川智能首次融资时估值已超5亿美元,下一轮融资,估值将超10亿美元,目前新一轮融资也非常顺利。

百川智能初始团队拥有包括前搜狗、百度、华为、微软、字节、腾讯等知名科技公司以及其他创业公司核心成员在内的数十位AI人才。目前成员构成上,技术人士占比70%-80%,来自搜狗的旧部大概占到30%—40%。技术联合创始人陈炜鹏表示,搜狗之前各个业务线最优秀的干将如今基本在百川集结完毕,但百川同时也在面向国内大厂、初创和硅谷招聘各类人才。
值得一提的是,百川智能与清华系渊源极深,两位创始人均出身清华大学,王小川甚至因求学和创业几乎没有离开过五道口,被称为“清华东门守门员”。
百川智能的天使轮融资也有清华系的影子,清华大学资产管理有限公司参与了本轮投资,包括清华大学计算机系教授,中国工程院院士等众多中国人工智能学术界领军人物均对百川智能表示支持。
将搜索基因与大模型融合
在百川智能发布会上,王小川表示,因为百川智能之前有搜索基因,因此天然懂得如何从万亿网页中间去精选最好的页面,可以做到去重、反垃圾。在数据处理中,百川智能也借鉴了之前搜索的经验,能小时级完成千亿数据的清洗和去重工作。
AI大模型的原理主要是通过在大规模宽泛的数据上进行训练,以此来适应一系列下游任务的模型。其中涉及的关键技术和要素主要是数据、算力和算法等方面,搜狗作为曾经在国内市场份额排名前三的搜索公司,在数据获取、清洗等方面积累深厚。

王小川在采访中表示,百川智能在搜索增强系统中融合了多个模块,包括指令意图理解、智能搜索和结果增强等关键组件,通过搜索结合大语言模型技术来优化模型结果生成的可靠性。
这种方式不同于OpenAI将微软的搜索当作一个黑盒去使用,而是从非常底层的地方就开始将模型和搜索融合。具体到百川智能的 baichuan-53B模型,用户当有问询指令进来之后,它不只是调模型去回答,而是在发现模型里没有内在信息时,最后去调用搜索。
而对于大模型的发展方向,王小川认为只要的搭建在 Transformer在这个架构上的大模型,都是有机器幻觉的,即非时效性的问题。因此大模型未来要变成一个好的服务,需要有多个技术栈在一块,而不是从一个模型直接变成一个服务。模型和搜索会以新的形式融合在一块,而不是模型替代搜索。
中文内容更有优势
因为搜狗是基于中文内容的搜索引擎,因此百川智能在处理中文内容时天然比国外大模型公司更有优势。而目前国外开源模型更多是支持英文为主的西方语言,对中文内容的支持存在许多问题。
在王小川看来,互联网的网页可能是万亿量级的,但是实际用到模型训练的大概也只有百亿的量级。百川智能的团队背景是做了很多年的搜索,所以对中文互联网里面哪里有好的数据最清楚,并且再怎么把这些数据收集回来,质量做好,识别出来,团队都有很强的积累和方法论。
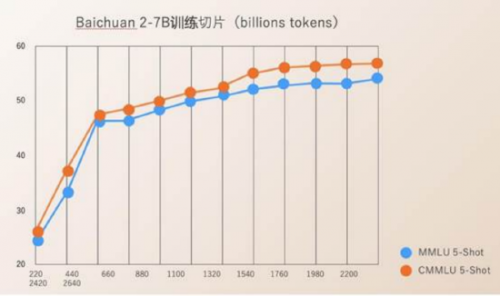
根据发布会信息,Baichuan 2大模型建立在上一代产品基础上,相比一代,Baichuan2数学能力提升49%,代码能力提升46%,安全能力提升37%,逻辑能力提升25%,语义理解能力提升15%,均处于开源模型最好水平。在MMLU、CMMLU、GSM8K等权威评估中,Baichuan2开源大模型均领先LlaMA2。
截至目前,百川开源大模型已经在开源社区总下载量超越500万。其中,Hugging Face首周下载量达百万,近一个月的下载量337万。而且在Github上,baichuan系列模型是星标月涨幅最快的中国大模型。
在企业端,已有超过200家企业已申请百川大模型开源和商业授权,并已将百川模型投入实际生产场景。企业涵盖互联网、软件和信息技术、金融、法律、教育、制造业、企业服务等众多领域,客户包括阿里云、腾讯、火山引擎、京东科技、顺丰科技、浪潮、中国农业银行、蔚来汽车等。
业内专家的声音
纵观国际市场,OpenAI和谷歌两大AI巨头都选择了闭源策略来保证自身优势地位,而Meta的LLaMA2则开启了大模型开源之路。如今随着百川大模型的开源,预示着国内大模型有望迎来高速发展的繁荣期,不少专家学者营业对此做出了积极评价。
清华大学计算机科学与技术系教授,计算机系主任尹霞表示:面对ChatGPT引发的大模型技术浪潮,我对王小川的技术把控力、组织协调力、坚韧不懈的能力都很有信心,深信王小川带领着他的团队,一定能够做出非常优异的产品。计算机系也将一如既往地支持王小川和他的团队,重启天工研究院,从科研合作方面助力王小川同学的再次出发。
清华大学人工智能研究院院长张钹表示:“ChatGPT是AI的重大突破,代表了未来AI发展的一个重要方向。建立以ChatGPT为基础的平台,需要充分地利用知识、数据、算法和算力这4个要素,需要高水平的企业家带领高质量的团队才能完成。王小川熟悉人工智能最前沿的进展,并且有坚实的工程实现和创新应用。同时,王小川也具有丰富的创业经验,是一位优秀的企业家。新创建的百川公司的团队很强,我相信他能够完成这个使命,并在未来的发展中给予全力支持。”
王小川曾在今公开表示,智能时代也会改写自工业时代以来的范式。曾经是专业化社会分工带来规模效应与效率提升,而未来会是逆专业化分工:之前需要很多公司协作完成的工作,会因为AI的赋能‘端到端’地完成。
如果王小川所言非虚,那么AI对生产关系的重塑已经只是时间问题,而随着大模型领域竞争日趋白热化,整个行业势必将在不断洗牌中迎来革命性产品,大模型的应用场景也将指数级拓展,从单一任务到多种任务,从通用领域到垂直领域,从生成式AI到决策式AI,从数字人到数字世界,我们正在向着一个新的虚拟世界形态前进。
那么,旧的互联网巨头们能否延续优势再创辉煌?如百川智能这样的挑战又将如何上演屠龙故事?帷幕已经拉开,结局正在上演之中。