据Gartner预测,到2026年,将有超1亿人与生成式AI一起工作,到2027年将有近15%的新应用由AI自动生成,无需人工参与。麦肯锡则预测,生成式AI将为全球经济发展带来2.6万亿—4.4万亿美元的价值增长。
AI技术带来的巨大未来预期,让国内众多企业趋之若鹜。截至2023年7月,中国累计已经有130个大模型问世,其中排名靠前的多为互联网科技巨头旗下产品,如百度的文言一心,阿里的通义千问等。在一众巨头奔赴大模型的盛况中,似乎唯独字节跳动显得比较沉寂,直到7月才出现零星消息,8月才发布名为“豆包”的语言大模型。

而事实上,字节很早便开始布局人工智能领域。早在2016年,字节就成立了人工智能实验室AI Lab,聚焦于自然语言处理、机器学习、数据挖掘等方面的研究。
到了今年2月,字节跳动在大模型领域的布局开始提速。据晚点Post报道,字节在战略上分三条路线同时进行,领导者分别是TikTok产品技术负责人朱文佳,Data-AML(数据-应用机器学习)负责人项亮,字节ALLab(人工智能实验室)总监李航。
若以学术和落地两个方向进行划分的话,李航团队更偏学术理论探索,朱文佳团队更趋向场景落地,项亮团队则处于中间位置。正因如此,朱文佳团队的发力点主要集中在能赋能自家产品的语言和图像两种模态上。
与此同时,字节跳动创始人ZYM的相关言论,也在很大程度上反映了该公司对AI的重视。今年4月,ZYM在2023公开信中表示,字节跳动无法错过AGI;AGI是抖音和TikTok在全球发现新增长机遇不可或缺的伙伴,可以解决字节跳动的第二曲线增长困境。
大模型服务平台:火山方舟
过去十年崛起的互联网大厂中,几乎都存在一个思维定式:自己搭台,请别人唱戏,阿里、腾讯、字节的主要业务莫不如此。而在这一次AI大模型浪潮下,几家巨头似乎再次想到了一块儿。
6月19日,腾讯发布了自家的大模型服务平台——腾讯云MaaS,其定位是依托腾讯云TI平台打造行业大模型精选商店,为B端客户提供MaaS(模型即服务)一站式服务,该平台技术底座来自腾讯全栈能力,能提供高性能计算集群HCC、高性能网络、向量数据库等基础设施。
仅一周后,字节旗下的火山引擎也发布了大模型服务平台——火山方舟,其运营模式是,在一个平台内提供多个模型,企业可同步试用多个大模型,选用更适合自身业务需要的模型组合。本质上,字节的这个业务是给国内大模型公司提供算力等配套服务,是一个“卖铲子”的角色。
对于入驻平台的大模型企业,火山方舟一方面能够大幅降低其触达海量客户的成本,以更小的代价在B端市场实现规模化。据QuestMobile报告,截至2023年6月,腾讯、阿里、百度及抖音的去重用户总量均超10亿,分别是12.12亿、11.83亿、11.05亿、10.11亿。此外,字节在海外还有8.4亿的日活用户,总体用户体量在全球范围内仅次于Meta。
另一方面,火山方舟平台主打严谨的安全互信机制,兼顾灵活性与安全性。为促进模型提供方和模型使用方的互信,火山方舟上线了基于安全沙箱的大模型安全互信计算方案,利用计算隔离、存储隔离、网络隔离、流量审计等方式,实现了模型的机密性、完整性和可用性保证,适用于对训练和推理延时要求较低的客户。

最重要的一点是,字节能提供源源不断的算力,让大模型企业在竞争中占据优势。为吸引大模型公司入驻火山引擎,字节跳动把抖音等业务的空闲计算资源极速调度给火山引擎,并比同行更低的价格出售算力服务。此外,有消息称,今年字节跳动向英伟达订购的GPU产品总价超10亿美元,接近英伟达去年在中国销售的商用GPU总和。在这种极度烧钱的行业现状下,字节的算力资源无疑是字节敢于做大模型服务平台的底气所在。
目前,火山方舟内已经集成了百川智能、出门问问、复旦大学MOSS、IDEA研究院、澜舟科技、MiniMax、智谱AI等多家AI科技公司及科研院所的大模型。
火山引擎总裁谭待表示,“十年前,中文互联网开始从PC时代转向移动时代,其中最大的技术创新就是个性化推荐算法。五年前,4G技术开始普及,带宽不再成为瓶颈,以抖音为代表的短视频,也正是在这次技术变革期间涌现出来的新体验和新交互。时间来到现在,大模型已经当仁不让拿起了技术革新和体验创新的接力棒。”
云雀大模型和“豆包”
2023年8月31日,首批通过《生成式人工智能服务管理暂行办法》备案的企业名单出炉,百度(文心一言)、抖音(云雀大模型)、智谱AI(智谱清言)、中科院(紫东太初大模型)、百川智能(百川大模型)、商汤(商量SenseChat大模型)、MiniMax(ABAB大模型)、上海人工智能实验室(书生通用大模型)8家企业赫然在列,此后这些企业可正式上线面向公众的大模型服务。
这是字节“云雀大模型”这一名称首次出现在媒体报道中,而此前字节已于8月17日公测了基于云雀大模型开发的AI对话产品“豆包”,该应用有网页端、ios和安卓客户端,预置了英语学习助手和写作助手两个功能。
云雀大模型和“豆包”的关系,类似于食材和菜品。因为“大模型”通常是在无标注的大数据集上,采用自监督学习的方法进行训练得来。而要将其应用在具体的垂直场景中,需要对模型进行微调或二次训练,“豆包”便是由云雀大模型微调得来。
云雀大模型的定位是一个多媒体内容生成和内容理解的AI大模型,该模型基于字节神经网络加速器开发,可以根据用户输入的图片、视频、音频、文字等信息,生成各种类型和风格的多媒体内容,如视频剪辑、音乐配乐、滤镜特效、字幕翻译等。它还可以对输入的多媒体内容进行分析和评价,如标签、分类、质量、风格等。

而据“豆包”官网介绍,其核心服务主要是AI对话,接入了利用深度神经网络、强化学习等技术训练的大规模语言模型以及其他模型及服务,模型采用对话格式,可以根据用户输入的指令,通过自动化分析后生成参考信息。
技术背景方面,“豆包”基于深度学习,可以对输入的文本进行预测和生成。其语言模型基于Transformer架构,具有高效的并行处理能力和良好的语言理解能力;“豆包”的训练数据来自互联网上的大量文本,包括新闻、博客、小说、论文等。这些数据被用于训练“豆包”语言模型,以提高其语言理解和生成能力;“豆包”的训练过程中使用了多种优化算法,包括随机梯度下降、Adagrad、Adadelta等。
多模态大模型BuboGPT
除了语言大模型“豆包”,字节在8月还发布了一款处于测试阶段多模态大模型BuboGPT,该模型能够处理包括文本、图像和音频在内的多模态输入,并具有将其回复与视觉对象相关联的独特能力。
简单来说,它不仅可以理解图像、音频和文本,并将这些理解与文本输入和输出相结合,还可以精确定位和描述图像中的物体以及声音的来源。
BuboGPT的诞生是建立在大型语言模型(LLM)的基础之上,BuboGPT创造性地将LLM与其他组件相结合,使其能够一起处理图像、音频、文本并推理它们之间的关系。BuboGPT的核心功能主要体现在以下几个方面:
一是多模态理解能力。BuboGPT实现了文本、视觉和音频的联合多模态理解和对话功能;二是视觉对接能力。BuboGPT能够将文本与图像中的特定部分进行准确关联,实现细粒度的视觉对接;三是音频理解能力。BuboGPT能够准确描述音频片段中的各个声音部分,即使对人类来说一些音频片段过于短暂难以察觉;四是对齐和非对齐理解能力。BuboGPT能够处理匹配的音频-图像对,实现完美的对齐理解,并能对任意音频-图像对进行高质量的响应。
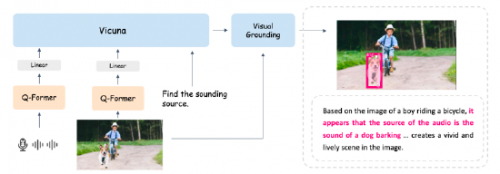 BuboGPT 的框架
BuboGPT 的框架
相比其他多模态大模型,BuboGPT利用文本与其他模态之间的丰富信息和明确对应关系,提供了对视觉对象及给定模态的细粒度理解。为了实现多模态理解,BuboGPT使用了一个共享的语义空间,并构建了一个视觉定位pipeline,其中包括标记模块、定位模块和实体匹配模块。
相比于大语言模型“豆包”,显然BuboGPT在创新方面走得更远,其开创的“visual grounding”,能将视觉元素和语言线索联系起来。BuboGPT核心贡献是三个模块:标记模块、定位模块和实体匹配模块。标记模块为给定图像生成相关的文本描述符,而定位模块则生成语义掩码或框,从而精确指出每个描述符的空间本质。最后,实体匹配模块利用LLMs推理的敏锐性,在文本和视觉结构之间实现匹配。
显然,BuboGPT的出现和字节旗下业务密切相关。作为全球范围内的社交巨头,字节旗下拥有抖音等多个C端应用,在音视频上的应用场景非常丰富,多模态大模型BuboGPT可以从多个方面为这些社交应用进行赋能。
综合字节在B端、C端和学术端的三款产品,字节的AI大模型布局已经初见成效。尤其是多模态大模型BuboGPT,目前在全球范围内并无其他竞品。这得益于字节旗下短视频产品积累了丰富语料与标注数据,且字节在算法和算力上均走在行业前列。
另外,全球范围内的大模型竞争,其最重要的门槛还是在资金层面,这一点字节的优势也非常巨大。有消息称,字节2022年营收约800亿美元(约5496亿元人民币),较上年同期的617亿美元增长30%。同期腾讯的营收也不过5545.52亿元。

今年5月份,曾有媒体报道称,ZYM正在看一系列的OpenAI论文,甚至熬夜看,已经到了废寝忘食的地步。看来这位曾经的程序员,如今的互联网传奇人物,是真的准备打一场硬仗了。


