最新的人工智能助理可以通过结合不同类型的个人数据来提供更多上下文和对话式答案,但对于这种现象,公众是否应该更多的提高警惕?
事实上,人工智能助理已经存在多年了。毕竟Siri于2011年在iPhone 4S上首次亮相。但早期的人工智能助理最初的功能有限,有时即使在理想的情况下也很难给出有用的答案。然而,2022年底和2023年开始出现的新一波人工智能助理可以毫不费力地完成所有事情,从创建食谱到总结电子邮件,甚至为照片编写社交媒体标题。

由于生成式人工智能(即经过数据训练后可以根据提示创建内容的人工智能)的兴起,人工智能助理今年取得了飞跃。大约一年前,OpenAI凭借ChatGPT令世界惊叹不已,微软、谷歌、亚马逊和Meta等科技巨头在2023年灵活地将生成式AI融入他们的聊天机器人、搜索引擎和数字助理中。
但是显然新一批人工智能助理还需要得到大型科技公司的信任,这是一个相当庞大的体系问题,因为数据泄露、2018年剑桥丑闻等争议以及对隐私做法的调查动摇了公众对科技公司的信心。
过去十年,监管机构和公众对公司如何使用我们提供给他们的数据流提出了重大疑问。虽然采用新人工智能的好处,可能意味着我们每天使用的技术服务变得更加个性化。
在某些方面,OpenAI的ChatGPT、微软的Copilot和Google Bard等聊天机器人只是数字服务运营方式的演变。谷歌母公司Alphabet、Meta和亚马逊等公司很早就已经开始针对用户互联网浏览习惯的数据,以提供个性化内容、广告和推荐。
新的人工智能工具可能不需要更多的个人数据,但这些工具连接不同类型个人数据(例如我们的电子邮件和短信)之间的新方式引发了新的隐私问题。卡内基梅隆大学CERT网络安全部门技术总监马修·布特科维奇(Matthew Butkovic)表示:“我们现在可以看到这些工具是如何将各个部分组合在一起的,我们知道数据就在那里,但现在我们正在了解如何将其组合使用。”
新型人工智能助手的崛起
整个2023年,人工智能助理这项技术显然正在进行重大改革。
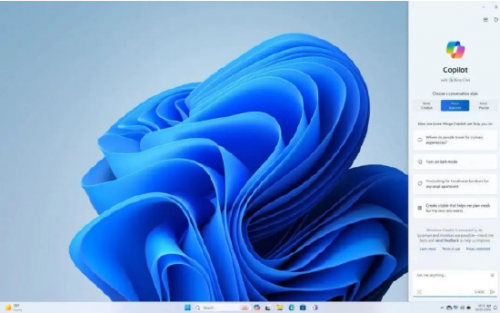
微软在9月21日的活动中详细介绍了Microsoft Copilot,它比这家PC巨头现已关闭的前个人助理Cortana更为复杂,其不仅仅回答“下周西班牙的天气怎么样?”之类的问题和命令。或“我的下一次会议是什么时间?”它还能够从应用程序、网络和设备中提取信息,以提供更具体和个性化的响应。
在9月21日的主题演讲中,Windows副总裁Carmen Zlateff展示了一个示例,说明Windows PC上的Copilot如何根据手机短信中的信息(例如即将起飞的航班的详细信息)回答问题。该示例强调了Copilot的作用不仅仅是根据网络或Microsoft帐户中存储的数据检索答案。
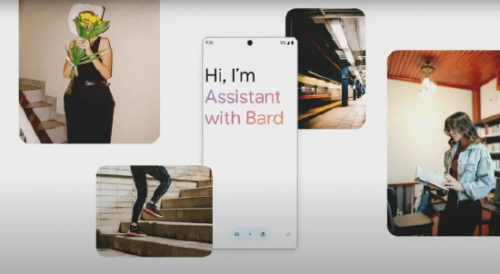
没过多久,谷歌就展示了生成式人工智能将如何在自己的助手Google Assistant中发挥作用。在10月4日的一次活动中,谷歌推出了Assistant with Bard,这是其人工智能助理的新版本,由对话式Bard聊天机器人背后的技术提供支持。
Google Assistant和Bard副总裁兼总经理Sissie Hsiao在活动中展示了这一点,她展示了“帮我查看本周我错过的所有重要电子邮件”之类的命令。她在演示中表示:“虽然Assistant非常擅长处理快速任务,例如设置计时器、提供天气更新和快速拨打电话,但我们一直设想一个功能强大的个人助理应该能够做更多的事情,但迄今为止,提供这种服务的技术还不存在。”
生成式人工智能几乎影响着我们与互联网互动的方方面面——从检索搜索结果到编辑图像。但微软和谷歌的声明代表了这些公司对人工智能助手的看法发生了根本性转变。它不仅仅是让这些人工智能助理成为更好的倾听者和对话者,就像亚马逊在9月份推出的升级版Alexa所做的那样。
微软和谷歌可能是使用生成式人工智能创建更智能助手的最大支持者,但他们并不是唯一的支持者。OpenAI去年通过ChatGPT掀起了生成式AI热潮,最近宣布用户将能够为特定任务创建ChatGPT的自定义版本,例如解释棋盘游戏规则和提供技术建议。这可能为任何人提供创建自己的专业数字助手的机会,OpenAI将其称为GPT。使用者所需要做的就是提供说明,决定希望GPT做什么,当然,还需要为其提供一些数据。
相信人工智能会以正确的方式使用数据
生成式人工智能可能标志着人工智能助手的一个转折点,即为他们提供他们所缺乏的情境意识和对话理解。但这样做也意味着为这些人工智能助手提供了一个更大的窗口来了解我们的个人和职业生活。但这种模式需要用户对人工智能系统的信任,以一种让人感觉有帮助而不是破坏性或令人不安的方式处理用户的电子邮件、文件、应用程序和文本。

卡内基梅隆大学的布特科维奇提供了一个假设的例子,说明与生成式人工智能助手合作可能会出错:假设用户要求人工智能助手编写一份有关特定工作相关主题的报告,如果数据没有正确分类,人工智能助手可能会意外地将敏感的客户数据编织到其报告中。“我们可能会在我们没有预料到的信息组合中看到潜在的新风险来源,”他说。“因为我们之前没有工具,也没有采取保障措施来防止这种情况发生。”
斯坦福以人为中心的人工智能研究所的隐私和数据研究员Jen King引用了另一个假设的例子。如果用户与家人进行长时间的电子邮件对话,讨论已故亲人的安排,这样的情境之下,用户显然不希望将这些通信纳入某些答案或报告中。社交媒体和照片库应用程序中已经有这种情况发生的先例,此后Facebook在2019年增加了更多控制措施,该公司使用人工智能来阻止已故朋友或家人的个人资料出现在生日通知和活动邀请推荐中,避免悲伤的情景再次出现。
除此之外,基于人工智能的生成应用程序和聊天机器人还面临着其他挑战,例如它们提供信息的准确性,以及黑客欺骗这些系统的可能性。科技公司意识到这些障碍并正在努力解决它们。

“我们知道数据就在那里,但现在我们正在了解如何将其组合使用。”卡内基梅隆大学CERT技术总监马修·布特科维奇(Matthew Butkovic)表示。例如ChatGPT同样鼓励用户对答案进行事实核查,并透露答案可能并不总是准确的。它还警告用户不要在该工具中输入敏感信息。Microsoft Copilot也在常见问题页面指出,不能保证回答正确,并表示Copilot继承了与Microsoft 365等企业产品相同的安全标准。它还表示,客户数据不会用于训练其大型语言模型。
但圣克拉拉大学马库拉应用伦理中心主任伊琳娜·拉伊库(Irina Raicu)对尚未解决的生成人工智能特有的新隐私漏洞感到担忧。在8月份的一篇博客文章中,英国国家网络安全中心描述了潜在的即时攻击可能是什么样子的示例。理论上,黑客可以在通过银行应用程序发送给用户的交易请求中隐藏恶意代码。如果此人向银行的聊天机器人询问该月的消费习惯,大型语言模型最终可能会分析攻击者的代码,同时查看此人的交易以回答问题。反过来,这可能会导致资金被发送到攻击者的帐户。
伊琳娜担心网络安全无法应对这些新威胁,她指出,近年来勒索软件攻击的兴起是网络安全解决方案发展不够快时,最有可能发生的情况。

当然我们有理由相信人工智能的繁荣,不一定会导致隐私问题激增。例如,白宫和欧盟已经在推动人工智能监管。与Facebook、Instagram和谷歌搜索等平台出现时相比,科技公司在隐私、安全、规模和影响力方面普遍受到更严格的审查。
但最终,我们仍然必须应对新技术带来的潜在风险。
“这没有绝对的事情,”布特科维奇说。“我们将生活在这个灰色空间中,至于这些人工智能对你生活的了解程度,则可能需要由你个人决定。”