首个AI程序员,演示视频大幅度造假???
不久之前震撼硅谷的Devin,再度震撼硅谷——但这次是被打假。
事情是这样的:油管程序员博主Internet of Bugs(以下简称光头哥)对Devin的视频进行了逐帧分析,逐一举证说明了Devin并不如演示中那般神奇。

甚至有“自己现写bug然后当场修复”的骚操作。
其它“罪证”,包括但不限于:
号称能解决任何Upwork任务,但演示中解决的问题并不是prompt要解决的那一个,做无用功;
看起来在修复bug,实际上修复的bug人类程序员根本就不会犯;
没有意识到简单两步就能解决问题,花里胡哨一顿操作,其实是自己把任务搞复杂了;
修改代码的水平一言难尽。
此外,光头哥花了半个多小时,把Devin演示视频中的upwork任务完成了一遍——而Devin完成任务可能用时6个多小时。
啊这这这,真是好、大、一、口、瓜!
要知道,其背后公司Cognition AI手握10块IOI金牌的活招牌,还在推出Devin当月宣布成功融资2100万美金。
推特和YC上已经吵翻天了,让这件事的讨论度高居不下。
我请问呢?真的很讨厌演示造假,让demo看起来轻松达到意料之外的技术进步。
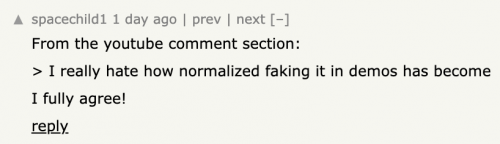
还有人表示自己很受伤,再也不会相信各种冒出来的创业公司的东西了。
emmmm……我还是把期待值全部留给OpenAI、Anthropic、DeepMind、FAIR这些公司和机构吧。

完整详情,一起接着往下看。
35年从业者逐帧验证
此次出来声张正义的光头哥,从事软件行业已经35年。他首先声明自己的立场:我并不反对高科技,但我确实反对过度炒作。
他自己也经常使用GitHub Copilot、ChatGPT、LIama2、Stable Diffusion。
事实上,在Devin刚推出时候,他就反对过“世界上第一个AI软件工程师”这一说法。
此次则主要针对的是一些更为具体的说法。
比如之前Devin号称能够靠处理upwork任务来赚钱的。但在真正的演示中Devin并没有做到这一点。
不信?没关系,光头哥带着逐帧的证据来了。
总结如下:
Devin所处理的任务并非随机,而是精心挑选;
与客户实际需求有很大的出入;
实际操作过程,数次自己创造bug然后再修复;
很多毫无意义的操作,相当于几十年前在C语言中才用的方法;
首先,来到了演示视频的2.936秒处,在屏幕左上角有显示他们搜索过这个内容。因此,这不是所谓“随机”选择的任务。
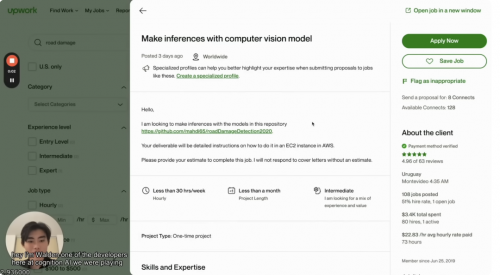
再来看客户给到的具体需求。真正需求为“我想要利用这个库来进行推理。你需要提供详细的操作指南。我不想讨论完成这项工作预计需要的时间。”
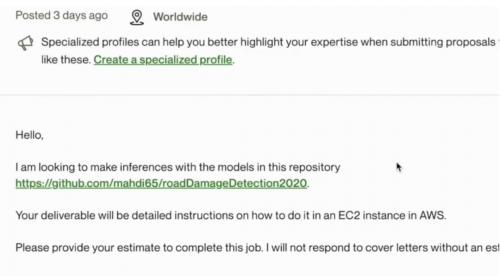
但给到Devin的需求却是:我希望利用这个模型在这个库中进行推理。请自己弄明白。
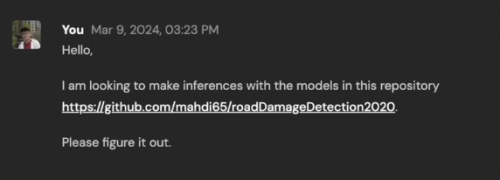
最后视频末尾出现的Devin生成报告中,也没有提及客户实际需要的内容。
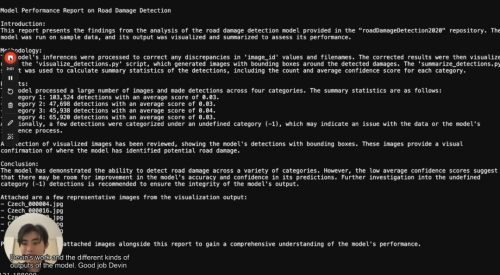
那么,这份工作的最终交付成果应该包括什么呢?

但Devin实际做了什么?
Devin第一次真正的尝试,是它修改了一个名为requirements.txt文件,其中规定了代码所依赖的库版本。视频中提到它正在更新代码,但实际上更像是修改配置文件。
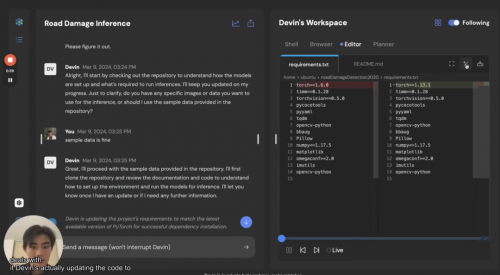
然后根据需求,需要Devin能建立自己的推理能力,并仅需使用样例数据即可。但实际项目要比这个复杂得多。
结果很快,Devin就遇到了第一个命令行错误——打开图像失败、文件未找到、无此文件或目录等。但在光头哥实际复现时并没有出现,结果研究发现,代码仓库压根就不存在这个文件。
这相当于Devin自己创建了个bug,然后再修复bug。在接下来的操作中,Devin经历了很多次这样的“自建自修”。
不能说十分有用,只能说完全没有必要。
接下来,再来看看代码库中这样一个readme文件。正如视频所展示的那样,readme文件清晰地说明了该文件的功能和用法。在页面右侧,甚至还有一个小按钮,点击它就可以复制整条命令,然后粘贴到命令行窗口中,按下回车即可运行。
但Devin完全没能理解,而又是自创了个项目。而写的那段从缓冲区读取数据的代码十分糟糕。
于是光头哥发出了灵魂拷问:
这不就是几十年前在C语言等中才用的方法吗???
这种做法显然已经过时,正常人用Python谁还会再写这个代码。这种代码很难调试,它逻辑复杂,难以理解,很容易出现细微的错误。
此外,代码库中还存在一个真正的错误,但Devin既没有发现也没有修复。
然后光头哥用谷歌搜索,按照GitHub 上一条相关评论修改了代码,只花了1分07秒,问题就解决了。
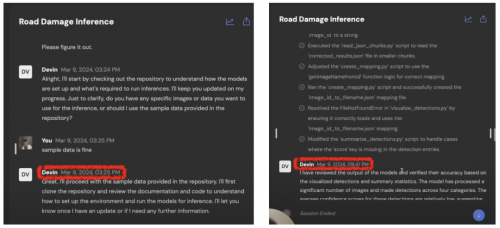
最终光头哥总共花了35分55秒复现了Devin的工作,而Devin实际花了多长时间呢?
如果细看视频Demo,就会发现Devin处理工作前后有6个小时20分钟的间隔。
视频的前部分显示的是3月9日下午3:25 的时间戳,但后半部分却显示的是当天晚上9:41。
而逐帧细看就有会发现一些奇怪且毫无意义的操作。
比如head -N 5 results.json | tail -N 5这个命令,它表示取这个JSON 文件的前五行,然后再取这些行的最后五行。
正确的做法应该是”head-5 results.json”。那个-N 是多余的。只要说 -5 就可以,不需要那些多余的东西。
最后光头哥锐评,AI现在生成的内容有很多都十分愚蠢,反倒会让事情变得更为复杂。
当看到它的任务列表时,会觉得:哇,Devin做了很多事情。但实际上可能并非如此。
网友:至少掌握了看起来很忙的技巧
对于此次Devin造假翻车,不少网友对现阶段AI产品炒作嗤之以鼻。
我真的很讨厌现在演示造假变得如此正常化
甚至还列出了三大炒作典范:Devin、rabbit、Humane。

也有网友调侃:Devin至少掌握了看起来很忙的技巧。

嗯?打工人有被内涵到。
不过也有一些支持的网友,比如这位沃顿商学院的教授Ethan Mollick。
他声称自己有早期访问权,在体验中发现真的很有趣。
他认为现在将Agent视作“炒作”为时尚早,未来几个月Agent的能力将十分强大。
号称“世界首个完全自主的AI软件工程师”
有意思的是,演示造假事件爆出来的时间,距离Cognition AI推出Devin仅过去了一个月。
咱们一起来回顾一下。
一个月前的3月13日,Cognition AI在推特上介绍了自家推出的Devin,并称其为“世界上首个AI软件工程师”。
只需一句指令,它可端到端地处理整个开发项目。
主创介绍,Devin在长程推理和规划上面下了很大功夫,可以规划和执行需要数千个决策才能完成的复杂软件工程任务。
具体来说有6大功能:
端到端构建和部署程序,可以解决的不只是代码问题,还包括与之相关的整个工作流;
自主查找并修复bug;
训练和微调自己的AI模型;
修复开源库;
为成熟的生产库做贡献;
超强学习能力,实时补足知识和能力短板。
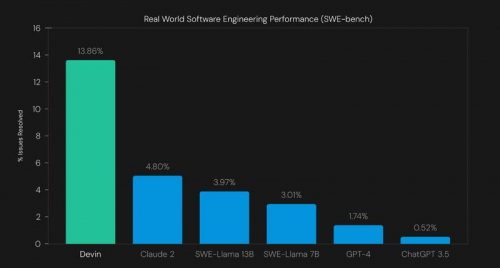
Devin完整技术报告中显示,在SWE-bench基准测试中,无需人类辅助,Devin可解决13.86%的问题
——这个数据看起来不高,但其实已经超过了此前所有AI大模型的成绩。
目前数一数二的GPT-4,在同个测试中的成绩只有1.74%,且必须配备一个人类,提示它要处理哪些文件。
当时的Devin团队一副没在怕的样子。
虽然没开放公测,但陆陆续续给出了一些内测名额。
在互联网上搜索一番,发现上手体验过的人给的买家秀反馈是这样的:
热衷AI的沃顿商学院教授Ethan Molick试过后,认为其新颖的实时交互方式是最值得关注的。
他要求Devin开发一个解释“创业公司融资中的股权稀释”的网站,随后透露,AI还无法在没有任何帮助的情况下,自主且无差错地完成这项工作。。
但也有人直接表示,体验过后确实是有被震撼到。
巧的是,截图中的这个首批内测体验者Bubna哥,是AI基础设施创业公司Modal Labs的CTO。
后来他和Devin还联手搞了个新闻。Devin用自家老板的账号,潜入Modal Labs的工作群,和Bubna哥一番交流过后,根据回复调整了代码方案,解决了一个技术问题。

△图中的发言人背后其实是Devin
当然,Devin还镀了一层光环,那就是背后公司Cognition,虽然是个小初创,但在招人信息中明晃晃写着:
我们团队手里握着10块IOI金牌呢~
技术演示和团队背景都吸睛Max,直接给Devin的传播力度添砖加瓦。
比如,GitHub三万Star项目MetaGPT就上新了“开源版Devin”,名为数据解释器(Data Interpreter):
阿里Qwen成员Binyan Hui等人开启了OpenDevin项目,一个月过去已经在GitHub揽星21.5k;
普林斯顿那边动作更快,用GPT-4打造了开源SWE-agent,开箱即用,可修复GitHub存储库中真实bug。
在25%的SWE-bench测试集上,它实现了与Devin演示视频中相似的准确度—— 解决了12.29%的问题。
还有各个大厂也开始入驻自己的AI程序员……
One More Thing
结果现在发生这件事儿,怎么说呢……
往好了想,真是救大命了,所有的程序员们都要松口气了,还好还好,AI暂时还无法端到端端走我的饭碗。
往坏了想,真是要了命了,这么一个备受关注的明星项目居然是个只能活在视频里的demo。
难道世界真的是个巨大的草台班子???